OpenAI が WebRTC スタックをゼロから再構築 — 低遅延 Voice AI をグローバル規模で届ける
Realtime API を支える舞台裏。既存ライブラリを捨て、スタック全体を自前で組み直した理由とは
テキストと画像を扱う LLM が当たり前になった今、Voice AI は次の競争軸になりつつある。OpenAI が公開した技術ブログは、Realtime API を支えるインフラ——特に WebRTC スタック の全面再構築——の舞台裏を明かす内容だ。公開要約をベースに、このエンジニアリング判断が持つ業界的意味を読み解く。
なぜ WebRTC なのか
WebRTC(Web Real-Time Communication)は、ブラウザ間でのリアルタイム音声・映像通信を実現するオープン標準だ。シグナリング、メディア転送、コーデック交渉を包括する規格で、ビデオ会議ツールや VoIP アプリが広く採用してきた。
OpenAI が Voice AI の配信基盤として WebRTC を選択した理由は明快だ。ブラウザ標準で組み込まれているため、ユーザー側に追加インストールが不要であり、既存の Web・Mobile アプリへの統合コストが最小になる。音声の双方向ストリーミングを最初から想定した設計であることも、リアルタイム LLM との相性が良い。
既存ライブラリでは足りなかった理由
OpenAI がゼロから再構築した事実は、「既製品では目標を達成できなかった」ことを示唆する。具体的な理由として推定されるのは以下の点だ。
1. グローバルレイテンシの最適化
300ms 以下の End-to-End 遅延を目標とする場合、リージョン間のエッジ配置とシグナリングの最適化を、アプリケーション固有の要件に合わせて精密にチューニングする必要がある。汎用ライブラリは共通の最適化しか施せず、個別チューニングが難しい。
2. 大規模同時接続への対応
ChatGPT のユーザーベースで Voice AI を展開するということは、峰値では数百万のセッションを同時処理する可能性がある。汎用の WebRTC ライブラリはこのスケールで動作する設計を前提としていない場合が多い。
3. AI モデルとの密結合最適化
WebRTC スタック がユーザーの音声を処理して LLM に渡すまでの経路で、バッファリングの戦略・コーデックの選択・パケットロス補正のパラメータはすべてトレードオフになる。OpenAI 独自の音声モデルが要求する入力品質と出力レイテンシに最適化するには、スタック全体を自前で持つ方が有利だ。
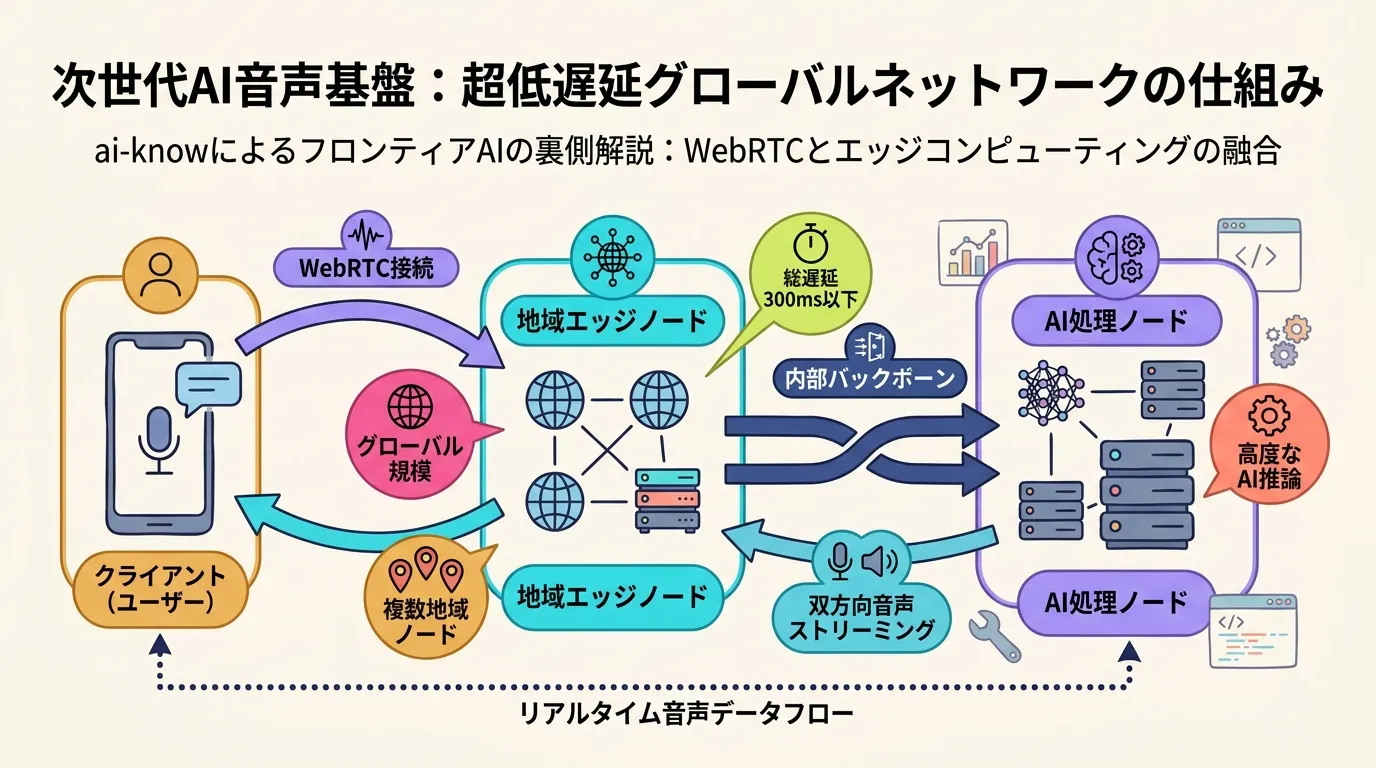
アーキテクチャの構造:推定モデル
公開情報から推定される WebRTC スタック の概念的な構成は次の通りだ。
クライアント(ブラウザ / アプリ)
↓ WebRTC(SRTP / DTLS)
リージョナルエッジノード(最近傍のリージョン)
↓ 内部高速回線(低レイテンシ VPC 間接続)
AI 処理ノード(音声 → テキスト → LLM → テキスト → 音声)
↓ WebRTC(SRTP / DTLS)
クライアントエッジノードがユーザーの最近傍に置かれることで、インターネット経由のレイテンシを最小化する。内部回線(専用ファイバー / 低レイテンシ VPC 間接続)で AI 処理ノードに送ることで、パブリックインターネットの不確実性を排除する設計だ。
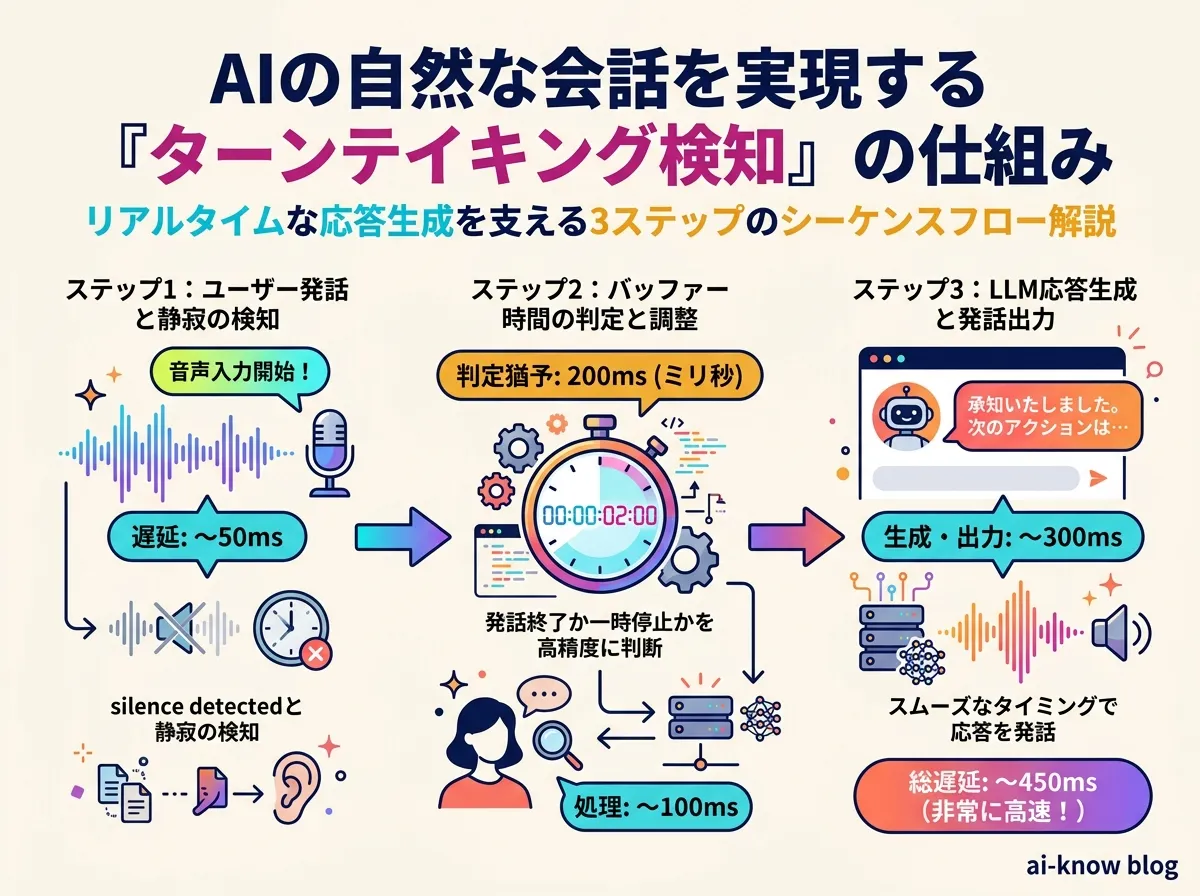
ターンテイキングの難しさ
Voice AI の技術的難関のひとつが 自然なターンテイキング(話者交代)の実現だ。人間の会話では、相手が少し黙っても「考えている」のか「話し終わった」のかをコンテキストから即座に判断できる。AI はこれを音響的な特徴(無音の長さ・音量変化・抑揚パターン)と言語的コンテキストを組み合わせて判定する必要がある。
判定が遅ければレスポンスが遅延し、早すぎれば相手の発話を遮断する。この精度と速度のバランスこそが リアルタイム LLM の差別化ポイントになりつつある。
Voice AI の競争環境
今回の OpenAI の動きは、Voice AI が「テキスト LLM の付加機能」から「独立した競争カテゴリ」へ移行したことを示す。同時期に xAI Grok Voice や Google Gemini Live が並走しており、インフラ強度が Voice AI の品質上限を決める時代に入っている。
既製の WebRTC ライブラリに乗った競合と、スタックを自前で持つ競合では、中長期の最適化速度に大きな差が開く可能性がある。OpenAI の「ゼロから再構築」の判断は、コスト対効果の観点では重い投資だが、音声品質・レイテンシ・スケールへの長期的な制御を手放さない選択でもある。
まとめ:インフラが Voice AI の品質上限を決める
WebRTC スタック の全面再構築は、一見地味なインフラ作業に見える。しかし、グローバルスケールで低遅延・自然なターンテイキング・高音声品質を同時に実現しようとすれば、既製品の組み合わせでは限界が来る。OpenAI の選択は、Voice AI を本気のプロダクトカテゴリとして定義した意思表明でもある。
参考:How OpenAI delivers low-latency voice AI at scale(OpenAI News、2026)